










Последняя работа компании Flare research статья представляет новый подход к искусственному интеллекту (ИИ), в котором объединение ИИ с блокчейном приводит к созданию более безопасного и точного ИИ.
Консенсусное обучение (CL) обеспечивает совместный ИИ в различных областях применения, позволяя разрабатывать более точные и надежные модели ИИ. CL особенно подходит для интеграции ИИ в чувствительные к данным отрасли, такие как здравоохранение или финансы, улучшая процессы принятия решений и повышая общую операционную производительность и эффективность, что, в свою очередь, может привести к снижению стоимости услуг для конечного потребителя. Это может привести к значительному улучшению качества обслуживания пациентов, более точному финансовому анализу или более эффективному выявлению мошенничества, а также к другим преимуществам. В отличие от большинства существующих реализаций ИИ и блокчейна, которые обеспечивают доступ к централизованному машинному обучению (ML) через блокчейн, CL использует блокчейн для создания децентрализованных моделей ИИ.
Мотивации
В последние годы все больше внимания уделяется распределенным средам, в которых данные и вычислительные ресурсы распределены по нескольким устройствам. Этот сдвиг вызван требованиями современных базовых моделей, таких как большие языковые модели и модели компьютерного зрения, которые требуют значительных объемов данных для обработки. В этой распределенной, но все еще централизованной среде децентрализация становится фундаментальной потребностью, обусловленной несколькими ключевыми мотивами.
Централизованные методы сопряжены с рисками, поскольку полагаются на единственную доверенную сторону, что ограничивает их использование в основном в рамках одного предприятия и сдерживает их более широкое распространение. Кроме того, такие архитектуры не только повышают уязвимость к потенциальным атакам или системным сбоям, но и вызывают опасения по поводу конфиденциальности и безопасности данных. Напротив, децентрализованные методы имеют явное преимущество: они позволяют пользователям разрабатывать персонализированные локальные модели, отвечающие их конкретным требованиям и предпочтениям, в то время как централизованные подходы часто не обладают гибкостью, необходимой для такой настройки. На фоне этих ограничений консенсусное обучение становится децентрализованным решением в области ML, обеспечивающим большую устойчивость, конфиденциальность и адаптивность, а также снижающим риски, присущие централизации.
Преимущества консенсусного обучения
Протоколы консенсуса необходимы для обеспечения безопасности децентрализованных бухгалтерских книг и защиты сетей блокчейн от вредоносных атак. Использование механизмов консенсуса для ИИ имеет множество преимуществ, среди которых мы выделяем следующие:
- Повышенная производительность. Методы CL используют данные каждого из участников ансамбля, что снижает предвзятость и повышает способность моделей к обобщению на основе невидимых данных. CL также может привести к более точному ИИ по сравнению с централизованными методами, в первую очередь благодаря способности блокчейна стимулировать сотрудничество, что приводит к более высокому мастерству в объединении различных данных, полученных от различных моделей. Это достигается за счет многократного локального агрегирования, когда каждый участник оценивает прогнозы соседних моделей и объединяет их для повышения точности. Это один из первых случаев, когда ИИ может получить значительные преимущества от интеграции с блокчейном.
- Безопасность. В присутствии злоумышленников, пытающихся внедрить скрытые цели, целостность моделей CL остается бескомпромиссной благодаря встроенным функциям безопасности механизмов консенсуса. Это гарантирует, что системы ИИ не будут генерировать преднамеренные вредные предсказания или непреднамеренные неточности, которые являются отличительными чертами вредоносного ИИ. Таким образом, CL решает одну из основных проблем сообщества ИИ - защиту ИИ от использования в пагубных целях. Поддерживая целостность процесса совместного обучения, CL внушает больше доверия к системам ИИ, прокладывая путь к их ответственному и этичному применению.
- Конфиденциальность данных. В CL ни базовые данные участников сети, ни их индивидуальные модели не передаются ни на каком этапе. Фактически, не существует злонамеренных атак на сеть, способных нарушить конфиденциальность данных, поскольку они хранятся локально. Сохранение конфиденциальности не только поощряет сотрудничество, но и сохраняет конкурентоспособность. Кроме того, CL позволяет монетизировать данные с помощью искусственного интеллекта, особенно в случае с конфиденциальными или коммерческими данными, такими как данные о здравоохранении, преодолевая предыдущие проблемы, возникавшие в централизованных средах.
- Полная децентрализация. Данные и вычислительные ресурсы распределяются по сети участников, которые общаются между собой, не полагаясь на единый центральный сервер. Необходимость в децентрализации ярко проявляется в современных ML-приложениях в связи с потребностью в огромном количестве ресурсов и растущей сложностью ML-моделей. Децентрализованный ML становится более подходящим решением для сохранения конфиденциальности данных и обеспечения безопасности.
- Эффективность. Процесс обучения имеет низкую задержку и требует гораздо меньше вычислительного времени, энергии и ресурсов по сравнению с другими современными децентрализованными методами ML. Это делает CL особенно подходящим для приложений реального времени, где быстрое принятие решений и эффективное использование ресурсов имеют первостепенное значение.
Как это работает
Обучение на основе консенсуса расширяет возможности ансамблевых методов за счет этапа коммуникации, на котором участники обмениваются своими результатами (моделями) до тех пор, пока не будет достигнуто соглашение. CL - это двухэтапный процесс, который может быть реализован следующим образом:
- Этап индивидуального обучения. Каждый участник сети разрабатывает собственную модель на основе своих личных данных и других общедоступных данных. Это может быть как создание модели с нуля, так и использование больших предварительно обученных моделей и их тонкая настройка под свои нужды. Важно отметить, что участникам никогда не придется делиться конфиденциальной информацией о своих данных или модели. После завершения обучения участники готовят свои первоначальные прогнозы для тестового набора данных - это может быть набор данных, раскрытый через смарт-контракт, или, в качестве альтернативы, участники могут предлагать новые тестовые точки данных, например, через механизм Proof-of-Stake.
- Фаза коммуникации. Участники передают свои первоначальные прогнозы в сети в соответствии с протоколом консенсуса/сплетен. Во время обмена сообщениями участники постоянно обновляют свои прогнозы, чтобы отразить оценки других участников сети, а также уверенность в своих собственных прогнозах. Кроме того, участник может отслеживать качество прогнозов, полученных от остальных участников сети, и использовать это для улучшения процесса принятия решений. В конце этого этапа участники приходят к согласию ("консенсусу") относительно решения, которое считается оптимальным с учетом информации, доступной в сети. Затем этот этап повторяется для всех новых данных.
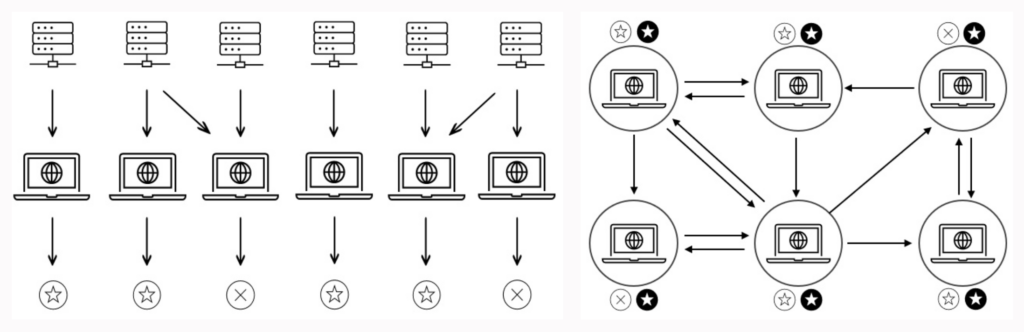
Подпись к рисунку: Пример работы CL для задачи бинарной классификации. (a) На первом этапе участники разрабатывают собственные модели на основе своих данных и, возможно, других данных, которыми охотно делятся другие участники. В конце этого этапа каждая модель определяет начальное предсказание (представленное полыми кругами) для любых входов тестового набора данных. (b) На этапе коммуникации участники обмениваются и обновляют свои начальные прогнозы, в конечном итоге достигая консенсуса по единому результату (представленному заполненными кругами). Эта фаза повторяется для любых новых входных данных.
Строго говоря, описанный выше алгоритм относится к сценарию контролируемого ОД - в частности, это ситуация, когда обучающие наборы данных уже помечены, а алгоритм делает предсказания для меток новых, невидимых, тестовых данных. Однако CL также может быть адаптирован к задачам самоконтролируемой или несамоконтролируемой ОД, когда участники имеют доступ только к частично или полностью немаркированным данным. Цели этих методов несколько отличаются, что требует от участников использования различных техник на этапе индивидуального обучения. Тем не менее, этап общения будет проходить аналогично приведенному выше описанию.
Чем отличается консенсусное обучение
Идея CL заключается в эффективном объединении знаний (в виде моделей искусственного интеллекта) из нескольких источников без обмена какой-либо конфиденциальной или ценной информацией или интеллектуальной собственностью. Такой подход призван защитить конфиденциальную информацию и одновременно обеспечить устойчивость к потенциальным рискам, исходящим от злоумышленников. CL опирается на весьма успешную парадигму ансамблевого обучения, которая предоставляет мощные методы для объединения нескольких моделей в одну. Методы ансамблевого обучения опираются на принцип "мудрости толпы", используя коллективные знания толпы, которые превосходят знания любого отдельного члена.
В последние годы появилось несколько блокчейн-реализаций сервисов ИИ, демонстрирующих инновационные подходы к интеграции ИИ в децентрализованные сети. Например, Bittensor облегчает выводы ИИ (вывод моделей) в своих доменных подсетях, взвешивая предсказания "майнеров" с помощью теоретико-игрового механизма. FLock.io предлагает платформу для объединенного обучения (другой тип распределенного обучения), хотя и с централизованным агрегатором, использующим блокчейн для проверки обновлений моделей и вознаграждения участников. Другой пример - Ritual, который эффективно управляет рынком ML-моделей через свой протокол Infernet, где запросы на запуск конкретной модели отправляются владельцу модели.
CL отличается от других своим особым методом агрегирования, при котором прогнозы отдельных моделей проходят через безопасный протокол сплетен для достижения согласия. Таким образом, CL использует блокчейн для создания децентрализованных моделей ИИ, в то время как существующие реализации позволяют получить доступ к централизованному ОД через блокчейн. Основное внимание уделяется обеспечению более точного и безопасного ИИ за счет совместной работы, в то же время позволяя субъектам, владеющим частными, часто конфиденциальными данными, присоединиться к системе, обеспечивая при этом конфиденциальность их данных.
В итоге
Консенсусное обучение представляет собой революционную возможность реализовать машинное обучение непосредственно на децентрализованных бухгалтерских книгах, таких как блокчейн. Благодаря этой инициативе мы становимся свидетелями появления нового подхода, при котором технология блокчейн может кардинально улучшить существующие инструменты ИИ. Это открывает захватывающие возможности для инноваций и безопасного сотрудничества в традиционно чувствительных к данным секторах, таких как здравоохранение, создавая основу для внедрения методов совместного ОД. Кроме того, устойчивость методов КЛ перед лицом вредоносных факторов способствует повышению доверия к системам ИИ, укрепляя их надежность и целостность.
